5. Don't Type - Use the Translation Memory
If something was translated before, you’ll get the translation automatically
If the next segment – or something similar – was translated before, memoQ will spot that and insert the translation immediately after you confirm the previous segment:
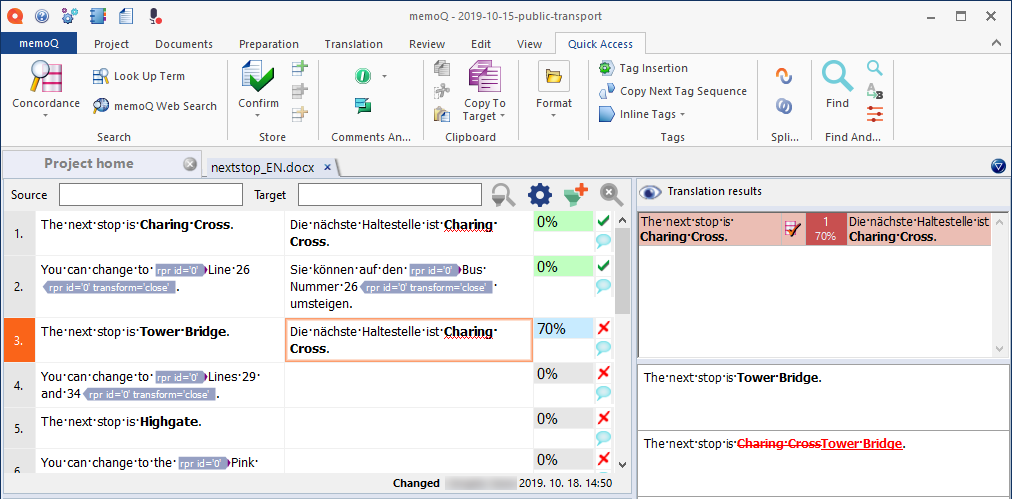
memoQ does this by looking in the translation memory that you use for the project. In the example, the translation of ‘The next stop is Charing Cross’ was saved when you confirmed the first segment. Segment 3 (‘The next stop is Tower Bridge’) is similar enough to be recognized.
But be careful: memoQ inserted the translation with ‘Charing Cross’, which you need to edit into ‘Tower Bridge’ before you confirm the new segment.
Look right: memoQ helps you find out the difference. In the right pane (called Translation results), you will see a list of suggestions that memoQ has for the current segment. (Right now, there is only one.) When you select a suggestion, the three boxes below will show the difference.
The first box shows the text that you need to translate. The second one shows the source text that was found in the translation memory. In the second box, the differences are marked with deletions and insertions (“tracked changes”). The differences appear as if the text in the translation memory were edited into the current text that you need to translate. Parts that come from the translation memory appear as deleted; parts in the current segment appear as inserted.
The third box shows the translation that was found in the translation memory.
This suggestion is called a translation memory match. memoQ gives a score to each match, judging the similarity between the text in the document and the text in the translation memory. The score, called the match rate, is a percent value (in this case, 70%). The match rate is an attempt to show how much you need to work on the stored translation before it is right for the current source text.
When the source text is exactly the same as the one in the translation memory, it’s called an exact match, and the score will be 100%. When the source text and the previous and the following segment is the same as in the translation memory, it’s called a context match, and the score is 101%. When the text is the same, but numbers, tags, formatting, or punctuation are different, the score will be between 95% and 99%. When the score is below 100%, it’s called a fuzzy match.
memoQ knows about numbers
The next segment will also have a match from the translation memory. It contains numbers again. Let’s see what happens to those:

In the translation memory, memoQ found a match that had the number 26. In the text, there were the numbers 29 and 34. When memoQ inserted the match with 26, it replaced 26 with 34 – so the numbers were, in a fashion, updated.
The segment had two numbers, though. Before you confirm the segment, you still need to insert the other number, and adjust the German translation to the plural:

Note that the tags were also inserted automatically – because you inserted them when you translated the second segment, and memoQ also saved that information to the translation memory.
Notice the lightning sign next to the translation. The lightning sign indicates problems that memoQ spots automatically: extra or missing spaces, extra or missing tags, or in our case, missing numbers. The lightning sign is called a quality-assurance warning or QA warning.
Because you inserted the second number, the lightning sign will disappear when you confirm the segment.
There are more ways to benefit from translation memories. See the documentation about translation memories, match rates, and the Translation results list.
Comments
0 comments
Please sign in to leave a comment.